HumanoidBench
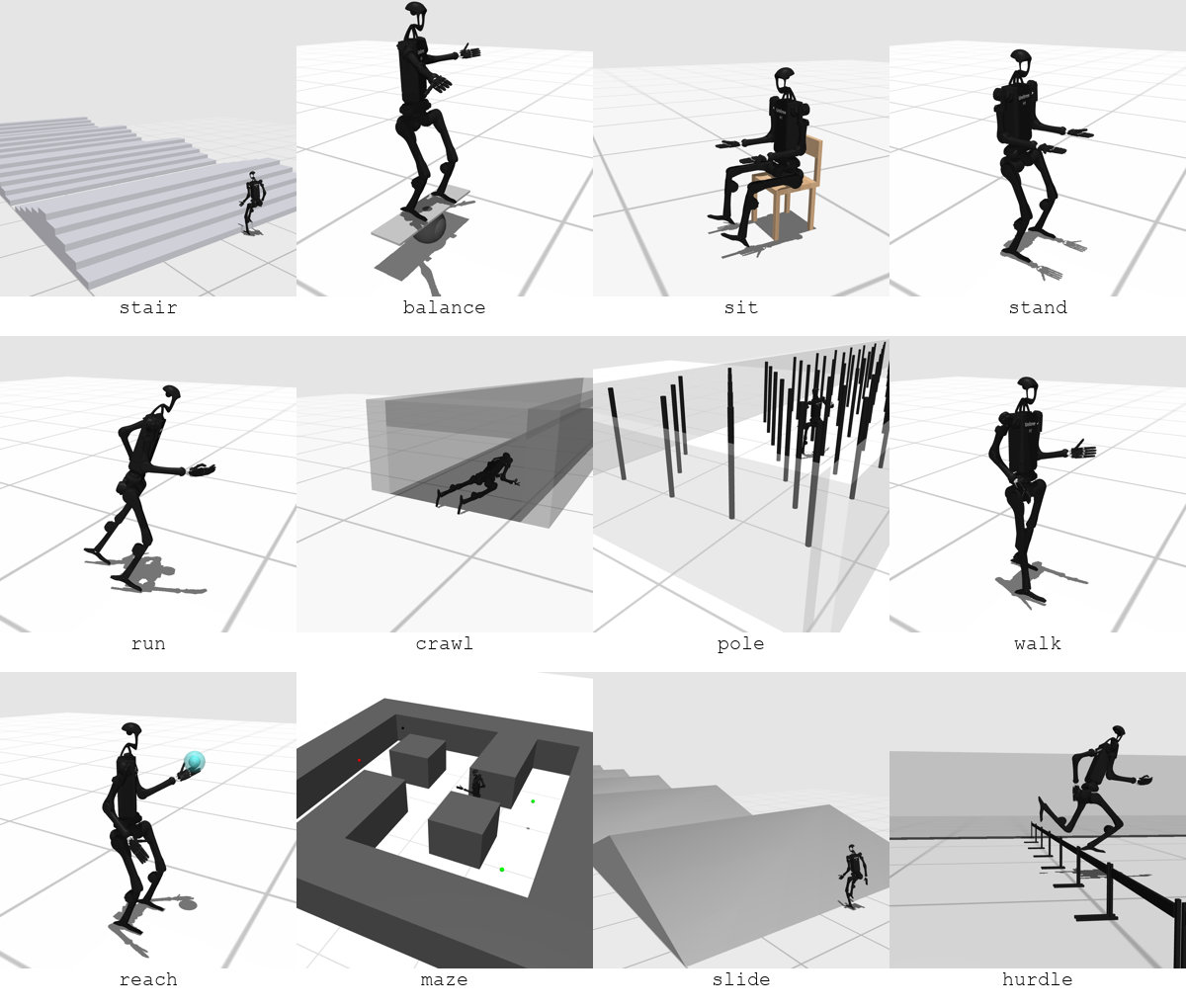
Locomotion
"Static" Manipulation
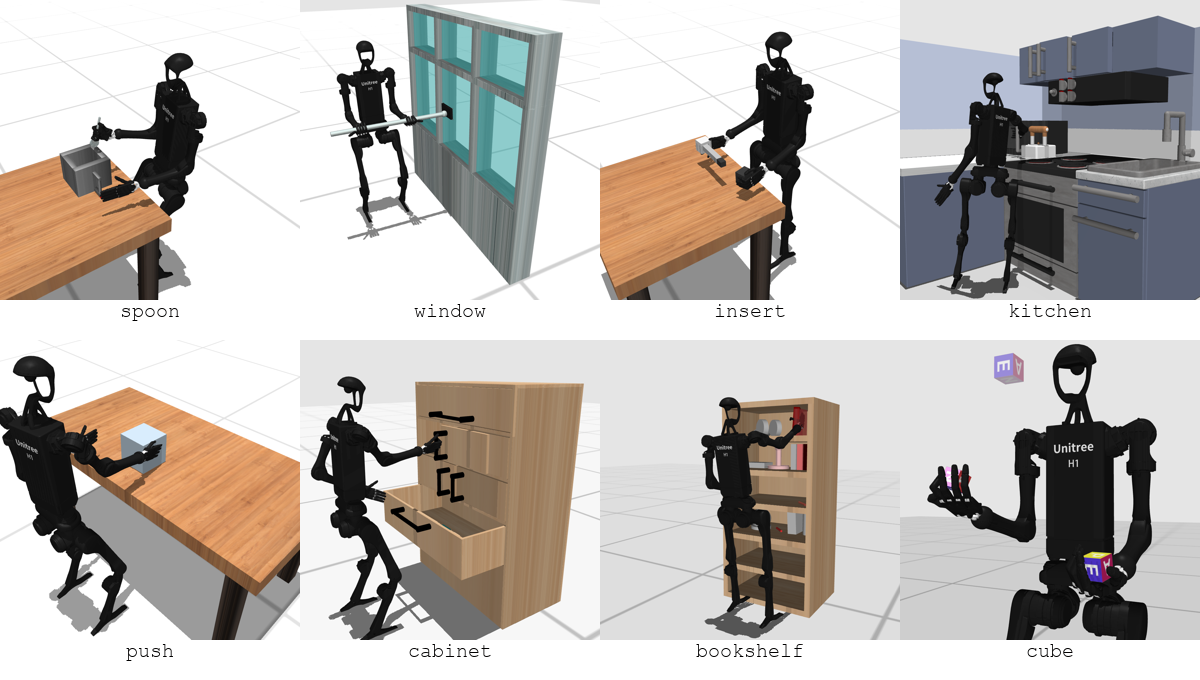
"Dynamic" Manipulation

Simulation Environment
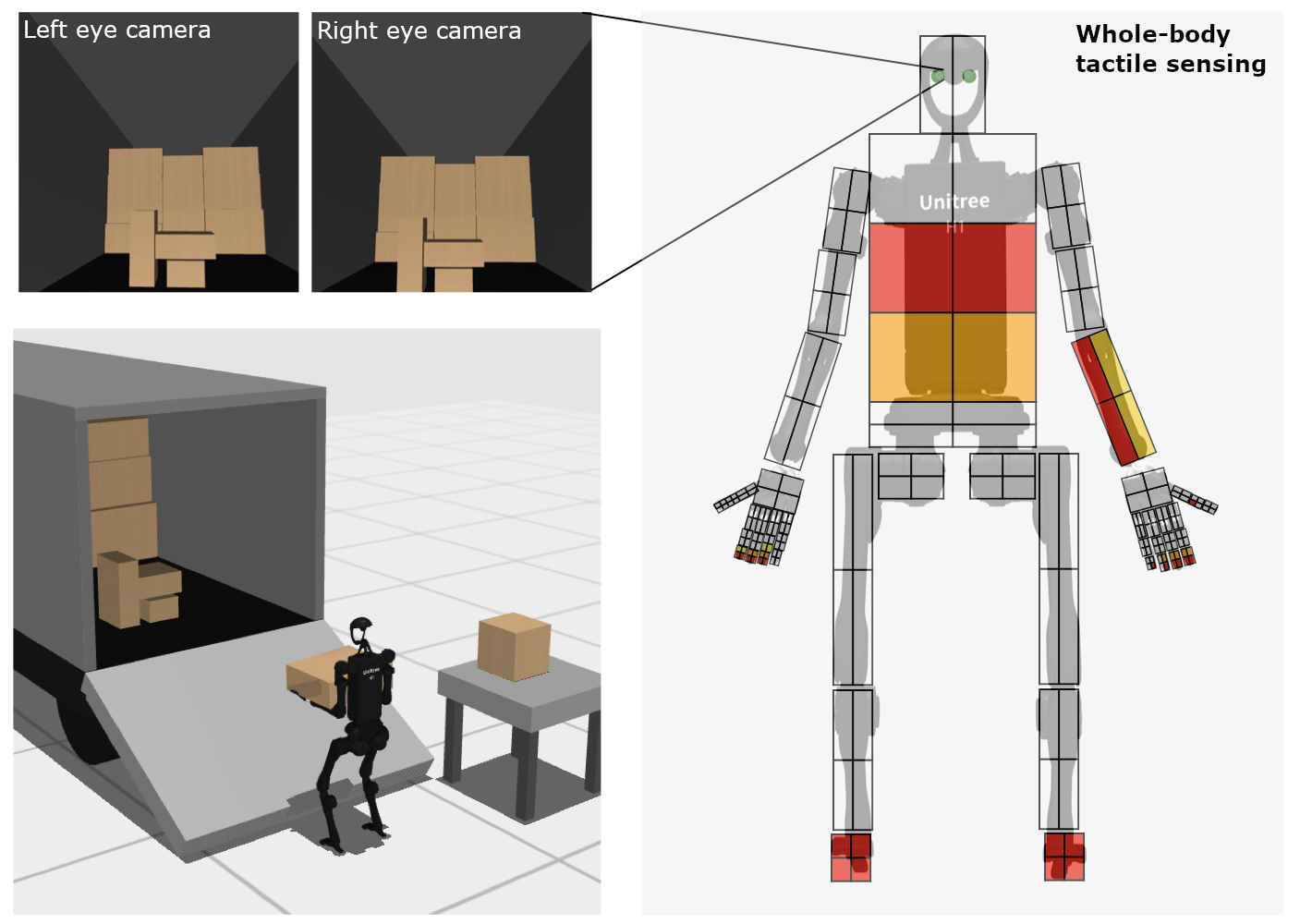
Observation Space
- Proprioceptive robot state (i.e. joint angles and velocities) and task-relevant environment observations (i.e. object poses and velocities).
- Egocentric visual observations from two cameras placed on the robot head.
- Whole-body tactile sensing using the MuJoCo tactile grid sensor. We design tactile sensing at the hands with high resolution and in other body parts with low resolution, similar to humans, with a total of $448$ taxels spread over the entire body, each providing three-dimensional contact force readings.
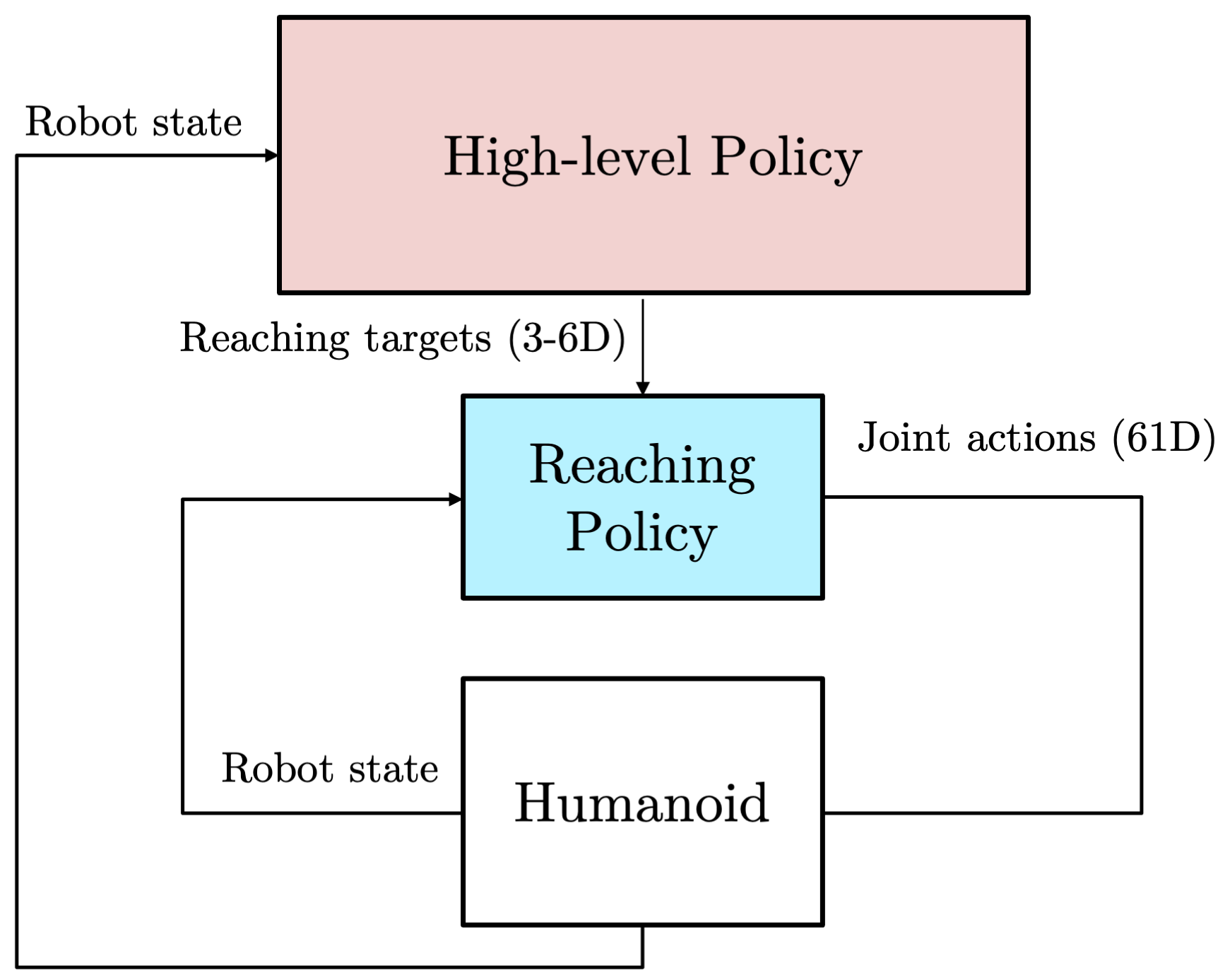
Hierarchical Reinforcement Learning
We benchmark a variety state-of-the-art reinforcement learning algorihtms on all tasks. Our results show how these end-to-end (flat) algorithms struggle with controlling the complex humanoid robot dynamics and solving the most challenging tasks. In fact, many of such tasks require long-horizon planning and necessitate acquiring a diverse set of skills (e.g., balancing, walking, reaching, etc.) to successfully achieve the desired objective.
We argue that these issues can be mitigated by introducing additional structure into the learning problem. In particular, we explore a hierarchical learning paradigm, where one or multiple low-level skill policies are provided to a high-level planning policy that sends setpoints to lower-level policies.
As an example, in the push task we use a one-hand reaching policy (trained with massively parallelized PPO using MuJoCo MJX) as a low-level skill, which allows the robot to reach a 3D point in space with its left hand.
push
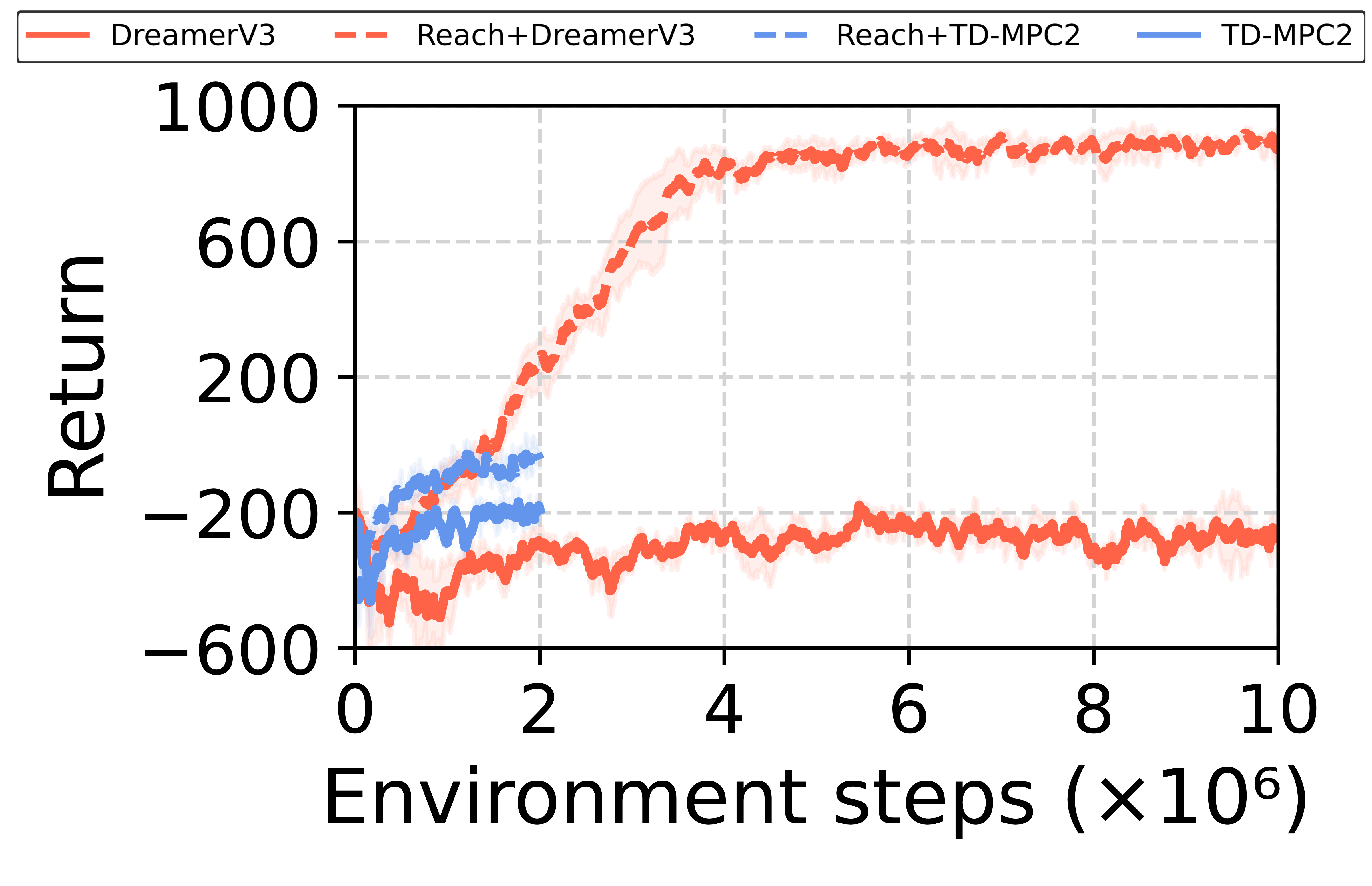
Low-level reaching policy (left hand)
Low-level reaching policy (two hands)
Vast Opportunities for Future Research!
With HumanoidBench, we set a high bar with complex everyday tasks, in the hope to stimulate the community to accelerate the development of whole-body algorithms for humanoid robots with high-dimensional observation and action spaces.
Many of the tasks are still unsolved — the videos below show a non-exhaustive collection of failure modes.